Starting a discussion thread for people for improving a project!
Hi, I’m Aadarsh, a freshman studying Computer Science at the National Institute of Technology, Tiruchirappalli. I’ll be working on building a Taxonomy Editor for GSoC 2022 this summer.
This project is at its planning stage and we’d love your feedback regarding this project.
Some details about the project are mentioned below:
Requirement Analysis
Currently, we have set the following requirements for the application:
Creation of a backend for parsing taxonomies
Implement CRUD of elements in a taxonomy
Provision for quick search of a component
Build hierarchy visualizations for taxonomies
Implementing validation of a taxonomy modification
Architecture
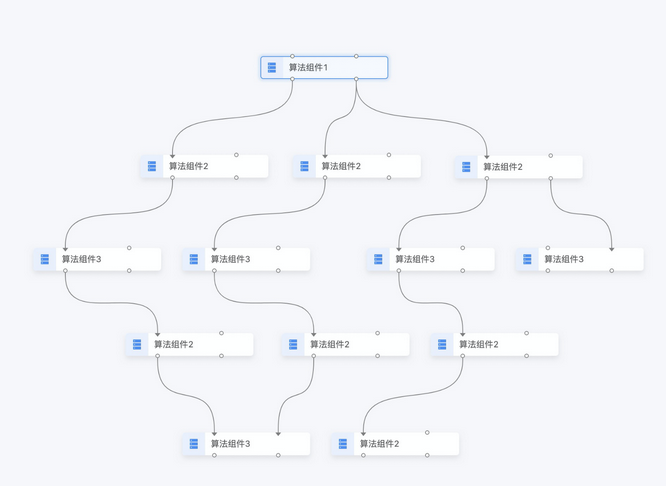
This issue clearly contains the initial architecture planned for this project.
Feedback
We would love to know your feedback on adding any other requirements, or about any workflows that you follow while editing taxonomies.
Any ideas regarding the architecture and design are much appreciated.
Feel free to drop your suggestions in this thread!
On the visualization front I didn’t see anything interesting and dedicated to DAG that are not too complex for our job (that does not look too much like a graph, which is messy). So I guess folder hierachy metaphore is ok, although incomplete ? Maybe we could explore what genealogy visualization software do, as they are kind of an extreme case of that. The closest is class hierarchy diagrams for software, but I think it’s a bit complex too.
but where the arrow would cross (because of multiple parents / children) but they would only be indicative.
What would be more important is to arrange my parents in levels of depth (from top to bottom), siblings on same level, and children underneath, by depth also.
To compute “level”, my intuition is that the longuest path from top to element is the best choice (it’s better to have a long arrow than an element above one of its parent).
You would of course never display whole taxonomy, but only surrounding elements to a specific entry.
@aadarshram, Speaking with @charlesnepote I understand we should not focus so much on vizualizing whole graph but a single item.
That is main page should be the one around one item.
We could put translations, synonyms, and properties.
Charles suggest there are simple tools that would help a lot, like building the url to wikipedia, and other nice features, knowing if the category is present in open food facts, how many entries it haves etc.
List of entries that may have common words could be useful.